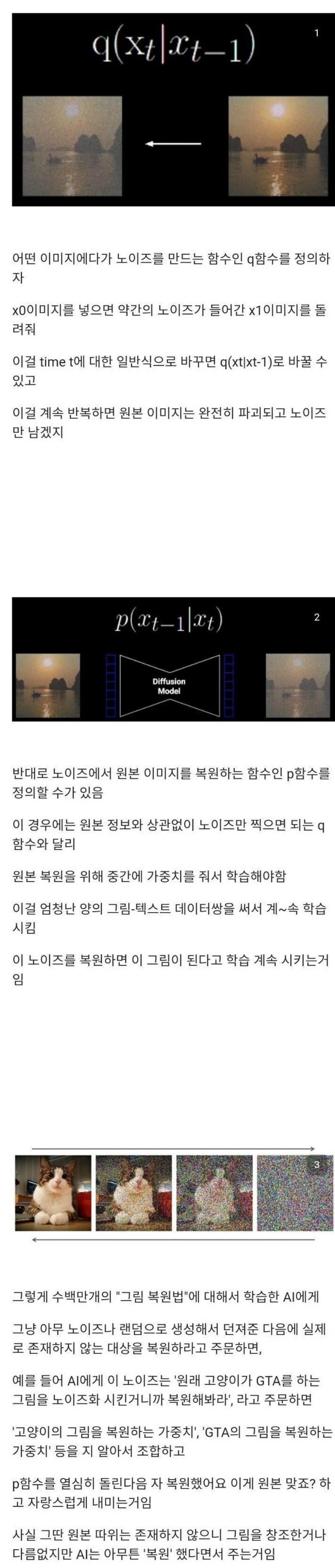
|
:: 게시판
:: 이전 게시판
|
- 모두가 건전하게 즐길 수 있는 유머글을 올려주세요.
- 유게에서는 정치/종교 관련 등 논란성 글 및 개인 비방은 금지되어 있습니다.
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
22/10/11 07:27
글이 확실히 쉽긴 하네요. 저는 노이즈 관련한 장난도 쳐본적 있어서 더 그런 면도 있긴 합니다.
그것보다는 원본 복원을 위한 가중치를 어떻게 주느냐가 가장 핵심이자 어려운 부분으로 느껴지는데, 이걸 뭉개고 넘어가는 게 더 커보입니다. 그래서 어떻게 가중치를 주느냐면... 저도 모릅니다.
22/10/11 07:42
그림을 두고 미분 적분을 계속 반복하다가 중간에 튀어나오는 상수 C를 통제하는 식의 방향으로 발전시키는거다 로 이해하면 대략 비슷한건가요?
그림이 조금씩 달라지는건 그림이라 미지수가 여러개라 그런거구요??
22/10/11 08:10
네 대강 그렇게 생각하시면 될 거 같아요. 다만 그 상수 C 즉 가중치를 구체적으로 어떻게 보정하는건지는 AI만 알고 아무도 모릅니다.
22/10/11 08:53
머신러닝이 무언가를 배우는 과정은 인간 학습 방법이랑 비슷하군요
저거 하면서 수많은 비슷한 그림을 그려보면 확실히 실력이 늘겠죠
22/10/11 08:40
사람도 비슷하지 않을까요?
노이즈가 아니라 흰 캔버스고.. 원본은 머릿속에 있는 거니까… “이게 (머릿속의) 그게 맞지?” 하고 꺼내주는…
22/10/11 09:34
우리가 눈의 촛점을 흐리게하고 보더라도 대강의 정보를 파악하고, 빈 정보를 채울 수 있듯이,
AI도 희미한 그림에서 더 선명한 그림을 얻는다고 보시면 됩니다. 매우 희미한 그림 --> 희미한 그림 --> 약간 희미한 그림 --> 조금 선명한 그림 --> 선명한 그림
22/10/11 09:48
인간의 창작도 살면서 봤던 무언가가 쟤료가 되서 나오는거죠. AI가 진짜 특이점 비슷한 어떤 선을 넘게 되면 오히려 창작 부분에서 인간이 상상하지도 못했던 엄청난 것들이 나올수도 있다는 생각이 드네요.
22/10/11 09:49
아니 노이즈복원이고 뭐고 그러니까 "원래 고양이가 GTA 하는 그림" 이라는 명령을 어떻게 내리고 AI는 거기서 어떻게 가중치를 두는지가 핵심아닙니까 크크; 그거를 퉁치네..
22/10/11 10:13
딴 이야기를 하자면, 명령은 아직 문장으로 못내라고 키워드로만 내릴 수 있는걸로 알고 있습니다. “원래 고양이가 gta하는 그림”은 gta랑 고양이란 키워드 정도만 주는거죠.
그리고 창작 같아보여도 어쨌든 인터넷에 있는 무수한 작품들을 참조하고 학습하는거라 위처럼 키워드주면 실제로 고양이가 gta하는 그림을 그려줄 지 잘 모르겠네요. 유게에 연어 ai그림에서 알 수 있듯이 강물을 거슬러 올라가는 연어보다 회로서의 연어가 레퍼런스로서 인터넷에 많기 때문에 강물과 연어를 키워드로 입력해도 강에 널려있는 연어회만 그려대죠. 지금 ai일러의 손이 부자연스러운건 손동작은 생각보다 더 다채롭고 ai가 손동작의 의미를 이해 못하기에 레퍼런스가 많은 손동작 위주로 그리기 때문입니다. 그리고 바둑이랑 달리 최적의 수란게 존재하지 않아서 ai에게 요구하면 ai가 생각하는 최적의 한 장을 보여주는게 아니라 여러 샘플들을 보여주고 사용자가 그 중 하나를 선택해서 선별한단 점에서도 아직 ai가 예술을 이해한다기 보단 ‘마치 이중에 하나쯤은 니가 원하는게 있겠지’ 식의 박리다매죠.
22/10/11 10:18
(수정됨) 가중치를 어떻게 두어서 설정하는지는 AI만 알지. 아무도 몰라요. AI 모델 설계자도 모르고 연구자도 몰라요. 그래서 이걸 블랙박스(black box) 영역이라고 하는걸로 알고 있습니다.수백만개의 데이터로 수십~수백만번씩 학습시키는데 여기서 값이 조정되는 변수(가중치)들이 모델에 따라 적게는 수천개에서 많개는 몇백만개가 서로 상호작용하면서 조정되는거라 알 수 가 없죠
22/10/11 10:09
걍 일반 신경망 AI 생각하시면 됩니다.
입력이미지&키워드 에 대응하는 정답이미지를 학습하는거에요 지금 돌아다니는 일러스트AI 는 아마 정답이미지를 여러개의 태그(키워드)로 분류하는 방법에 신경을 많이 쓴것이겠죠 메타러닝등의 기법도 반영된것이겠지만 원론적으로는 그렇습니다.
22/10/11 12:45
(수정됨) 오토인코더에 대한 내용인것 같네요. 간단하게 설명하자면 중간으로 갈수록 신경망의 크기가 작아지고 중간에서 끝으로 갈수록 신경망의 크기가 커지는 네트워크를 설계하구요, 이걸 벡터 공간적으로 표현하자면 넓은 공간(원본 이미지) -> 좁은 공간(이미지가 어떻게 생겼는지에 대한 직관) -> 넓은 공간 (복원 이미지) 이라고 볼 수 있습니다. 우리 경험이랑 빗대어 말하면 그림 잘 그리는 사람에게 그림 어떻게 잘 그려요? 하면 디테일하게 설명할 수 없지만 그림을 곧장 잘 그리는 것처럼 신경망도 여러가지 경험(훈련 데이터) 을 압축(직관화) 해서 압축된 직관에서 다시 원본을 생성하는 개념이라고 보시면 됩니다. 요즘의 딥러닝이 대부분 이런 "압축 공간" 을 훈련시키고 그 압축된 공간에게 지도학습 데이터를 주는 방식으로 진행됩니다. 책을 많이 읽어본 사람이 글쓰기도 몇번 해보면 금방 잘하는 원리랑 비슷합니다. 그래서 몇년 전에 가장 핫한 주제가 어떻게 하면 가장 좋은 직관을 훈련시킬 수 있을까였고 요즘은.. 잘 모르겠네요.
|
||||||||||||||