|
:: 게시판
:: 이전 게시판
|
다시봐도 좋은 양질의 글들을 모아놓는 게시판입니다.
통합규정 1.3 이용안내 인용"Pgr은 '명문화된 삭제규정'이 반드시 필요하지 않은 분을 환영합니다.법 없이도 사는 사람, 남에게 상처를 주지 않으면서 같이 이야기 나눌 수 있는 분이면 좋겠습니다."
18/01/10 02:13
메모리 접근시간을 이용한 타이밍 어택은 고전적이지만 회피하기 참 어려운 방법이지요.. 성능 최적화를 해서는 안 된다는 의미라서.
AMD도 공격방법이 좀 더 복잡해지기는 하겠지만 어딘가에 비슷한 구멍이 있지 않을까 생각은 합니다.
18/01/10 02:29
네. 그냥 논문에서도 자기들이 AMD 프로세서에서 보안 취약점을 이용해서 데이터를 추출하는 데에 실패했을 뿐이지, 이런 취약점이 있긴 있다고 지적하고 있습니다.
말씀하신대로 굉장히 고전적이고, 회피하기 어려운 방법이죠.
18/01/10 02:20
우선 정성스러운 글 감사합니다.
최초 링크로 주신 글도 읽어봤는데요. 전자신문에서 쓴 글인데, 어떤 점이 잘못 설명된 것인지도 함께 알려주시면 더욱 이해하기 좋을 것 같습니다. 멜트다운에 대한 설명은, 적어주신 것에 비하면 과도하게 압축되어 있긴 하지만, 결국 실행되지 않은 프로세스의 데이터가 캐시메모리에 남아있고, 이는 접근권한이 없는 경우에도 접근이 된다는 내용이라,, 적어주신 내용과 실 사용자 입장에서 느끼기에 크게 다른 것은 아니지 않나 싶기도 해서요.
18/01/10 02:27
(수정됨) 네. 이게 쓰다보니 너무 늘어져서 그냥 간략하게만 설명하고 많이 쳐냈습니다.
기존 링크에서 잘못 서술된 부분은, 말씀해주신대로 실행되지 않은 프로세스의 데이터, 혹은 커널 영역의 데이터가 캐시 메모리에 남아있으며, 접근 권한이 없는 경우에도 접근이 된다는 내용입니다. 그런데 실제로는 데이터에 접근이 안 되거든요. 데이터를 직접 접근하는 것이 아니라 유저 메모리에 선언된 배열에 저장된 값을, 비밀 데이터의 실제 값을 배열 인덱스로 활용해서 캐시에 올려 두고, 메모리 접근 시간을 이용해서 저장된 데이터가 뭔지 유추해 내는 것이 멜트다운이라서, 조금 세부적인 내용이 다릅니다. 사실 실 사용자 입장에서는 어느 쪽이든 데이터가 유출된 것이니까 그닥 다를 것은 없습니다. 관련 일하는 공돌이만 이해할 세부사항이 다른 거죠. 다만 다른 건 다른 것이니까 논문 본 것 정리할 겸해서 써 봤습니다.
18/01/10 03:03
(수정됨) 방금까지 심심해서 위키에서 읽고 온게 side channel attack이었는데, 야밤에 pgr에서 이런 글을 만나니 매우 반갑네요.
그런데 exception handler 만나면 바로 OOE를 뭠추면 되지 않았을까도 생각이 드는데, Intel은 왜 지금과 같이 했는지와 AMD와 ARM의 방법은 무엇이었는지 궁금해지네요. 좋은 글 감사합니다.
18/01/10 03:37
말씀하신대로 exception handler를 만나면 비순차 실행을 멈추는 것도 하나의 방법이겠으나, 하드웨어가 복잡해지는 문제가 있어서 아무래도 선호하지 않는 것 같습니다. 그리고 exception handling 자체도 비순차 실행을 하면 성능이 떨어질 테니까요.
AMD, ARM에서도 이론적으로 멜트다운 문제는 발생할 수 있습니다. 실제로 연구팀도 멜트다운을 발생시킬수 있는 상황 자체는 실험적으로 만들 수 있다고 말하고 있습니다. 다만 그걸 사용해서 민감한 정보를 추출하는 데에는 실패했다는 거죠. 타사 CPU에서 이런 문제가 발생하지 않는 이유에 대해서는 여러 가지 가설만 제시하고 있는데, 본질적으로 멜트다운은 exception handling 과 load간의 data race 상황이고, 구조상 AMD CPU 등에서는 파이프라인의 깊이 등이 달라서 로드가 완료되기 전에 exception handling 이 끝났다거나 하는 상황이 있을 수 있다는 정도로만 서술되어 있네요.
18/01/10 03:45
예외 핸들러를 만나기 이전부터 해당 명령어들은 OOO로 실행되었기 때문에 그렇습니다. 물론 실행하기 전부터 특정 명령어에서 예외가 발생한다는 사실을 알 수 있으면야 좋겠지만 그건 이론적으로 불가능합니다. (정지 문제와 등가) AMD의 경우는 이런 식의 OOO를 하는 경우에도 커널 메모리에 대한 권한 체크를 합니다만, 이 경우 인텔은 그걸 제대로 하지 않았죠. 아마 하긴 할텐데 이렇게 유저->커널 모드로 전환되는 상황까지 생각이 미치지 못했거나 혹은 어차피 상태는 롤백되니까 상관 없을거라고 생각했던 모양인데... 진실은 그 쪽 엔지니어들만 알 듯.
18/01/10 08:45
제가 질문을 좀 간략하게 했는데 security 관련하여 exception handling이 발생할만한 branch나 memory load point등 에서는 ooe를 하지 않거나 security 결과까지의 시간이 monitor window를 넘는다면 bubble처리하는 식이라면 구현 불가능할 정도는 아닐 것 같아요.
어쨋거나 저도 그쪽 엔지니어들이 진실을 밝혀주면 좋겠네요. 흐흐
18/01/10 14:42
(수정됨) exception handling+특정 instruction 수행할 때만 뭠추는거라 전체 성능에서는 penalty가 크지 않을 것 같아요.
게다가 이런 security관련된 error는 bus에서 response로 올라올텐데 exception check하는 stage를 최대한 당길 수 있을테고 그러면 penalty가 더더욱 줄어들겠죠.
18/01/10 15:24
어떤 branch와 ld op이 문제가 될지 일단 가서 읽어보기 전에 미리 알 수가 없는데 미리 알아내서 OOE 안 하면 되는거 아니냐고 하시면... 음..
18/01/10 15:39
(수정됨) memory op 에 dep가 걸려한번 stall된 instruction은 ooe를 안하면 됩니다.
위의 예제를 다시보시면 2번 instruction은 어차피 1번 instruction이 완료되기 전까지는 ooe가 수행될 수 없습니다. 1번 instruction이 완료되고 exception check전까지 ooe가 수행되는 것이 문제죠. security error같은 것은 1번 instruction이 완료되는 순간 바로 알 수 있는 요소중 하나이니 exception체크 후 진행해도 penalty가 별로 없을 것 같다는 생각이었습니다. 그런데 이런건 일반인들끼리 생각하는 가설 가능성일 뿐이고 진실은 인텔/AMD 당사자들만 알겠죠
18/01/12 03:42
뭐 충분히 많은 자원을 들이면 그런 예측을 하는 것도 어느 정도 가능은 하겠습니다만, 현실적으로 볼 때 가성비가 좋은 엔지니어링은 아닐 것 같습니다. 문제가 100% 해결되는 것도 아니고요. AMD같이 엄격하게 권한 체크를 하는 것이 멜트다운에 대한 올바른 해법이겠죠. 근데 스펙터는 또 다른 문제라 현세대 성능 개선에 활용되어 온 기법 전반을 재점검할 필요가 있는 것은 맞습니다.
18/01/10 05:48
5. 멜트다운
에서 25번째 줄 정도에 막혔는데 두 번 읽으니 기적적으로 이해가 되었습니다. 36번째 줄 부터 이해가 다시 되기 시작하면서 두 번 읽으니 이해가 되네요. 좋은 글 감사합니다. 무엇이 어떻게 문제가 된 것인지 아주 쉽게 이해할 수 있었습니다.
18/01/10 08:56
좋은 글 감사합니다.
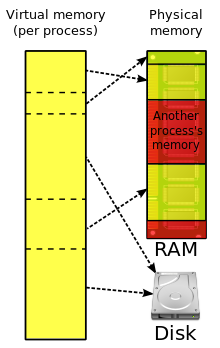
대부분 이해했는데 (혹은 이해했다고 착각...) 6번에서 커널 메모리가 프로세스의 가상 메모리 영역에 저장된다는 부분에서, 프로세스는 사용자가 접근할 수 있기 때문에 멜트다운이 가능한 것이고, 이를 패치를 해서 커널 메모리 자체를 다른 곳으로 옮겨 사용자가 아예 손댈 수 없도록 한다... 가 맞나요?
18/01/10 09:35
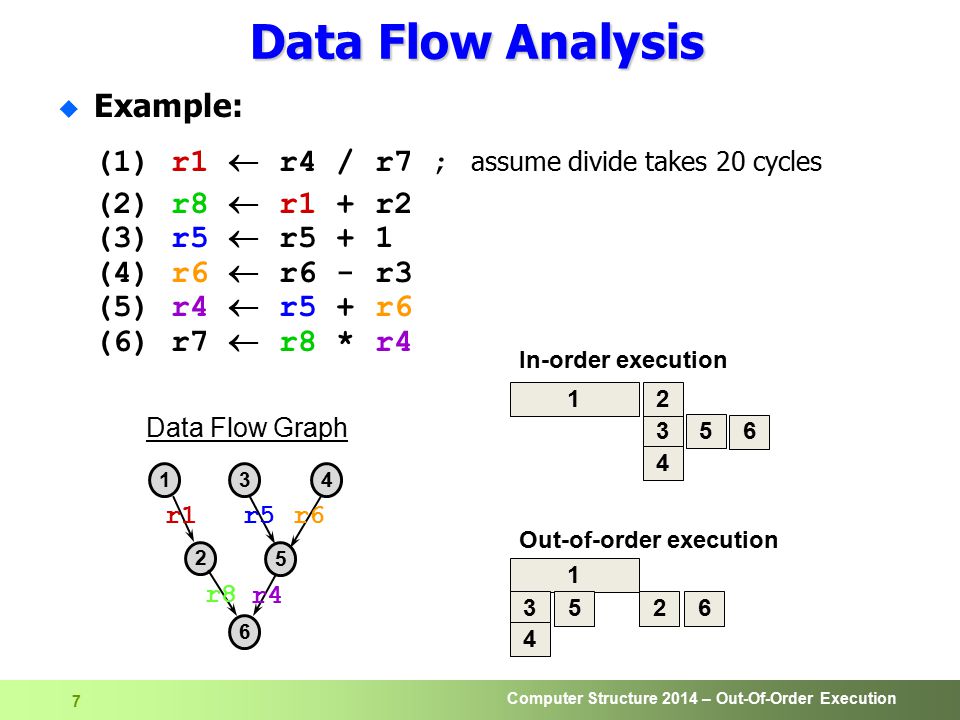
제가 이해한바로는
(1) r1 <- Load data from secret address (2) r2 <- Load data from array[r1] 이 부분에서 원래는 r1에 데이터를 일단 넣고(프로세스가 이미 알고있으니까) 예외처리를 기다렸다면 패치 후에는 r1에 데이터 자체를 못넣어서(프로세스가 아예 값을 모르므로) (2)로 못넘어간다는 의미로 이해했는데 이게 맞는지는 잘 모르겠네요 저도 이 부분을 좀더 상세히 여쭤보고 싶긴 했습니다
18/01/10 12:15
(수정됨) 맞는듯 합니다.
거기에 대한 결과는 프로세스 권한이 확인될때 까지 미리 케슁(파이프라이닝)하는 동작을 할 수 없고 결과적으로 시퓨가 권한을 확인하는동안 수행한 파이프라인 길이 만큼 공싸이클(노는)도는 일이 발생하겠죠. (파이프라인 길이에 따라 10이면 10배까지 느려지겠네요) 커널 공간과 유저공간을 빈번하게 교차 접근하는 연산에서 특히나 느려질듯 합니다.(네트워크라던가 등등의 I/O 작업들) 운영체제 프로그래밍 손 놓은지가 오래되서 가물가물 합니다.
18/01/10 13:22
사실 상세히 설명하려면 너무 더 설명해야 할 내용이 많아져서, 제가 간략히만 설명하고 넘어갔습니다.
말씀대로 패치 이후에는, 커널 영역에 접근하려면 문맥 전환이 발생하기 때문에, 비순차 실행을 통해 미리 메모리에 접근하는 일도 발생하지 않고, 결과적으로 정보가 유출될 가능성을 최소화시키는 것입니다.
18/01/10 10:38
이과만세! 공대만세!
어렴풋이 알고 있긴 했지만, 구체적으로 어떻게 해킹이 가능한지에 대해서는 잘 몰랐는데, 좋은 글 감사합니다. 문제는, 이런 문제가 있다는 걸 알게 되면, 해커들이 어떻게든 이용하려 들 텐데, 서버들이 걱정이군요. 특히나 클라우드 서버들... 해커들이란, "우린 어떻게든 방법을 찾아낼 것이다" 라는 집단인지라...
18/01/10 11:14
이미 아마존 같은 클라우드 업체들은 일괄적으로 패치를 완료했죠.. 문제는 퍼포먼스 드롭이 엄청 커서 기존과 같은 수준의 트렌젝션 처리를 위해 비용을 몇 배로 내야 한다는 것....
18/01/10 11:19
멜트다운 연구팀 정도면 어느정도 수준일까요? 구글 면접자 싸대기 때려도 입사되는 수준일런지..
암튼 덕분에 멜트다운에 관해서는 남들한테 아는 체 할 수 있게 되었습니다. 감사합니다.
18/01/10 14:57
제가 이해한대로 비유를 해보자면
기밀자료와 공용자료를 모두 다루는 도서관 사서가 있는데 사서는 모든 사용자의 기밀자료 접근권한을 알지는 못하기 때문에 사용자의 기밀자료 요청이 오면 접근권한을 알아오라고 비서1에게 시키고 비서2와 함께 기밀을 포함한 작업을 일단 진행하고 비서1이 기밀자료 접근권한이 있다고 알려주면 그대로 진행, 접근권한이 없다고 알려주면 그동안 한 작업을 다시 원상복구 시키면서 "너 권한없잖아 안알랴줌" 하는 방식으로 기밀자료 누출을 막으면서도 작업속도를 유지해왔는데 어느날 잔머리 굴리는 사용자한명이 기밀자료의 첫글자(숫자)를 사서에게 물어보고(예를들어 5), 사서에게 그 숫자에 해당하는 슬램덩크 권수를 공용책장에서 꺼내달라고 요구하자 사서는 늘 하던대로 비서1에게 이놈이 기밀접근권한이 있는지 알아보라 시키고 숫자5를 메모지에 적어서 비서2에게 슬램덩크5권을 공용책장에서 꺼내서 옆에 책상에 일단 올려놓으라고 시킴 비서2는 시키는대로 슬램덩크5권을 책상에 올려놓고 잠시후 비서1이 "저놈 권한 없던데요?" 하자 늘 하던대로 숫자5가 적힌 메모지를 파쇄 슬램덩크는 어차피 공용자료니까 그대로 책상위에 올려둠 그때 사용자가 다시 슬램덩크 1~10권 다 갖다주세요 라고 요청하자 사서는 비서2에게 슬램덩크를 꺼내오라고 다시 지시하고 마침 책상위에 이미 꺼내져있던 5권을 발견한 비서2는 사용자에게 5권을 먼저 던져주고 나머지 아홉권을 찾으러 나감. 사용자는 5권을 먼저 던져주는걸 보고 "미리 꺼내놓은걸 보니 아까 기밀숫자가 5번이구나" 라고 알게 됨 저는 이정도로 이해했네요. 적절한 비유일진 모르겠지만 전문용어 없이 이해하는데 도움이 될까 싶어 적어봅니다
18/01/10 17:42
정성글엔 추천이야! - 추천드렸습니다.
좀 찾아봐도 당췌 무슨소린지 모르겠어서 그냥 그런가부다 하고 있었는데 나일레나일레님의 글을 보니 궁금증이 한가지 생기는데요, 본문에서 [심플하게, 멜트다운을 막기 위해 대부분의 커널 공간을 프로세스의 가상 메모리에 매핑하지 않는 패치 -> 성능 하락]인 거면, CPU가 어디 꺼든 OS에 해당 패치가 이루어진 거니 유독 인텔만 성능 하락으로 떠들썩하지 않아야 할 것 같아서요. OS에서 커널 공간을 가상 메모리에 매핑하지 않겠다는데, 이걸 CPU 제조사에 따라 다르게 처리하진 않을 것 같은데...아, 성능으로 떠들썩한 건 결국 스펙터때문인가요?!
18/01/10 19:56
저도 그 부분이 궁금해서 조금 찾아봤는데, AMD는 멜트다운 버그를 통한 공격에서 상대적으로 자유롭기 때문에, AMD 프로세서를 사용할 경우에는 해당 패치가 비활성화됩니다.
성능 문제가 되는건 멜트다운을 방지하기 위한 패치가 맞습니다.
18/01/10 20:02
답변 감사드립니다. CPU 제조사에 따라 매핑을 하거나, 하지 않게 되는 게 맞았군요 그럼;; 헐..
본문 써주신 글도 그렇고, 위 도서관 사서 예시도 그렇고 멜트다운 취약점이 무엇인지, 그리고 왜 문제인지까지에 대해서는 확실히 인지가 되었는데도 불구하고 '근데 왜 인텔만..?!' 에서의 물음표는 여전하네요ㅠ
18/07/02 00:10
저는 설명을 위해 간략하게만 적어두었는데, 논문 작성한 애들이 실제로 멜트다운을 이용해 접근할 수 없는 정보를 보여주는 데모를 시연한 바 있습니다.
https://www.youtube.com/watch?v=RbHbFkh6eeE 실제 활용예는 사실 꽤 많을 수 있는데, 저는 아키텍처 하는 사람이고 보안 하는 사람은 아니라서 실 활용예를 들어드리기는 어렵네요.
|
||||||||||||